LLM
目前 PrimiHub 已支持基于 ChatGLM-6B 的联邦大模型,本文档将演示如何使用 PrimiHub 实现联邦大模型。
配置要求:最低显存需求 7G
步骤分为几个流程:
部署 ChatGLM-6B
ChatGLM 详细文档可参考这里,在此将做进一步的解释,以帮助用户充分理解该流程。
根据自己的GPU型号安装驱动
参考官网
安装 CUDA 版本 PyTorch
推荐使用显卡进行加速,并安装 PyTorch 以及相应版本的 CUDA。 首先确认本地安装的版本,如果为 True,则可以跳过该步骤
import torch
torch.__version__'2.0.0'
torch.cuda.is_available()
True
否则,需先在 PyTorch 官网 确认目前 GPU 版本要求,例如以下配置。注意,此时最好先确认 CUDA 版本,再进行 PyTorch 安装。

如果没有 CUDA,建议安装 CUDA 11.8,具体教程可见这里,选择系统需求,则会生成安装命令。
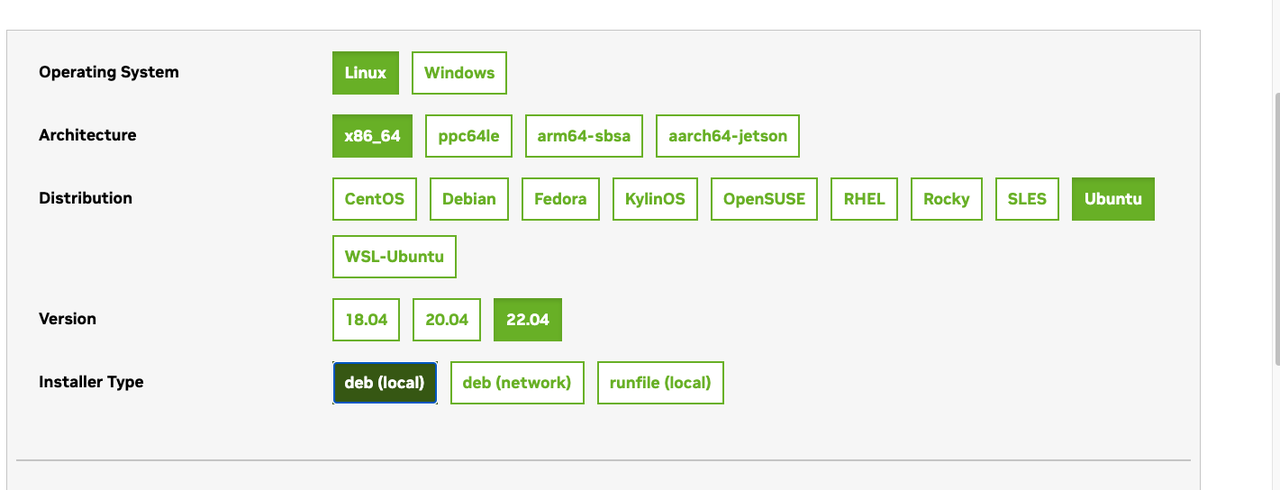

如果曾经安装过 CUDA,安装前最好将此前安装的版本删除干净,比如 /usr/local 下的 CUDA 可以直接删除或使用apt-get purge nvidia*
安装完成后,使用如下命令确认版本号以及是否安装成功。如果结果是11.8,说明安装正确。
/usr/local/cuda/bin/nvcc --version
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2022 NVIDIA Corporation
Built on Wed_Sep_21_10:33:58_PDT_2022
Cuda compilation tools, release 11.8, V11.8.89
Build cuda_11.8.r11.8/compiler.31833905_0
部署 ChatGLM
git clone https://github.com/THUDM/ChatGLM-6B.git
cd ChatGLM-6B
pip3 install -r requirements.txt
下载预训练模型:https://huggingface.co/THUDM/chatglm-6b-int4/tree/main 作为后续模型的输入。
配置完成后,在 ChatGLM-6B 下使用如下命令测试。注意:"THUDM/chatglm-6b" 需要替换为本地预训练模型的路径。
例如这里的示例是"~/czl/chatglm-6b-int4"
>>> from transformers import AutoTokenizer, AutoModel
>>> tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
>>> model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
>>> model = model.eval()
>>> response, history = model.chat(tokenizer, "你好", history=[])
>>> print(response)
你好👋!我是人工智能助手 ChatGLM-6B,很高兴见到你,欢迎问我任何问题。
>>> response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
>>> print(response)
晚上睡不着可能会让你感到焦虑或不舒服,但以下是一些可以帮助你入睡的方法:
1. 制定规律的睡眠时间表:保持规律的睡眠时间表可以帮助你建立健康的睡眠习惯,使你更容易入睡。尽量在每天的相同时间上床,并在同一时间起床。
2. 创造一个舒适的睡眠环境:确保睡眠环境舒适,安静,黑暗且温度适宜。可以使用舒适的床上用品,并保持房间通风。
3. 放松身心:在睡前做些放松的活动,例如泡个热水澡,听些轻柔的音乐,阅读一些有趣的书籍等,有助于缓解紧张和焦虑,使你更容易入睡。
4. 避免饮用含有咖啡因的饮料:咖啡因是一种刺激性物质,会影响你的睡眠质量。尽量避免在睡前饮用含有咖啡因的饮料,例如咖啡,茶和可乐。
5. 避免在床上做与睡眠无关的事情:在床上做些与睡眠无关的事情,例如看电影,玩游戏或工作等,可能会干扰你的睡眠。
6. 尝试呼吸技巧:深呼吸是一种放松技巧,可以帮助你缓解紧张和焦虑,使你更容易入睡。试着慢慢吸气,保持几秒钟,然后缓慢呼气。
如果这些方法无法帮助你入睡,你可以考虑咨询医生或睡眠专家,寻求进一步的建议。
如果上述能够正常运行,那么,恭喜你,库安装与模型预测没问题了。后续我们将说明如何进行模型训练。 安装如下依赖:
pip3 install rouge_chinese nltk jieba datasets
安装完成后,则可进行训练。训练很简单,在 ~/ChatGLM-6B/ptuning 下运行下述代码即可。
bash train.sh
cat train.sh
PRE_SEQ_LEN=128
LR=2e-2
CUDA_VISIBLE_DEVICES=0 python3 main.py \
--do_train \
--train_file AdvertiseGen/train.json \
--validation_file AdvertiseGen/dev.json \
--prompt_column content \
--response_column summary \
--overwrite_cache \
--model_name_or_path ~/czl/chatglm-6b-int4\
--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \
--overwrite_output_dir \
--max_source_length 64 \
--max_target_length 64 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--gradient_accumulation_steps 1 \
--predict_with_generate \
--max_steps 4 \
--logging_steps 1 \
--save_steps 3 \
--learning_rate $LR \
--pre_seq_len $PRE_SEQ_LEN \
--quantization_bit 4
参数说明:
- train_file 为训练数据文件
- model_name_or_path 为预训练模型的位置
- output_dir为落盘的位置 其他的参数比较容易,可以参考原项目地址。使用官方文档的数据集 AdvertiseGen 即可完成训练。确认训练能够完成后,我们将演示如何使用 PrimiHub 实现联邦训练。
使用 PrimiHub 实现联邦大模型训练
配置 Json 文件,修改 example/FL/chatglm/ChatGlm.json 参数:
{
"party_info": {
"Alice": {
"ip": "172.21.1.58",
"port": 50050,
"use_tls": false
},
"Bob": {
"ip": "172.21.1.63",
"port": 50051,
"use_tls": false
},
"Charlie": {
"ip": "172.21.1.58",
"port": 50052,
"use_tls": false
},
"task_manager": "127.0.0.1:50050"
},
"component_params": {
"roles": {
"server": "Charlie",
"client": [
"Alice",
"Bob"
]
},
"common_params": {
"model": "Chat_glm",
"process": "train",
"aggration_iter": 2,
"train_iter": 3
},
"role_params": {
"Alice": {
"path": "~/czl/ChatGLM-6B-Med/ptuning",
"train_file": "Meddata/train.json",
"validation_file": "Meddata/train.json",
"prompt_column": "prompt",
"response_column": "response",
"history_column": "history",
"model_name_or_path": "~/czl/chatglm-6b-int4",
"output_dir": "output/Alice_result",
"num_examples": 10
},
"Bob": {
"path": "~/czl/ChatGLM-6B/ptuning",
"train_file": "AdvertiseGen/train.json",
"validation_file": "AdvertiseGen/dev.json",
"prompt_column": "content",
"response_column": "summary",
"model_name_or_path": "~/czl/chatglm-6b-int4",
"output_dir": "output/Bob_result",
"num_examples": 10
}
}
}
}
相关参数配置说明如下:
- party_info:设置每个节点的 IP 和地址
- component_params:设置参数,其中:
- roles:设置每一个参与方的角色行为,例如 Alice 和 Bob 是 client,Charlie 是 server
- common_params是公共参数:
- aggration_iter:聚合几次
- train_iter: 每一轮聚合训练几轮
- role_params是每一方的参数设置:
- Path: 本地 ChatGLM-6B 项目的路径
- train_file, validation_file, prompt_column, response_column, history_column, model_name_or_path, output_dir: 同 train.bash
- num_examples: 每一方的数据量
配置完成后,通过下述代码即可发起任务。
submit example/FL/chatglm/ChatGlm.json
进行大模型的部署
训练完成后,可以在每一方的 output 路径下,看到 checkpoint 文件,类似:
primihub@primihub58:~/czl/ChatGLM-6B-Med/ptuning/output/Alice_result$ ls
all_results.json checkpoint-3 trainer_state.json train_results.json
primihub@primihub58:~/czl/ChatGLM-6B-Med/ptuning/output/Alice_result$
之后,使用python primihub/FL/algorithm/chatglm/load_model.py即可体验模型。
注意修改以下相关目录,以和自己的目录适配:
import os
import platform
import signal
import torch
import os
import torch
from transformers import AutoConfig, AutoModel, AutoTokenizer
# 载入Tokenizer
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model_name_or_path = "~/czl/chatglm-6b-int4"
pre_seq_len = 128
quantization_bit = 4
CHECKPOINT_PATH = "~/czl/ChatGLM-6B-Med/ptuning/output/Alice_result/checkpoint-3"